慧安蜂巢 | 大数据平台:深耕数仓建模,赋能企业智能决策
 发布时间:2024-12-19
发布时间:2024-12-19
 作者:慧之安
作者:慧之安
 来源:慧之安
来源:慧之安
慧安蜂巢大数据平台在模型设计方面提供了丰富的功能和灵活性,旨在满足不同业务场景下的复杂需求。通过以下几方面的强化扩展,平台确保用户能够构建出既高效又灵活的数据仓库模型,以支持多维度的分析需求。
01多样化的建模方法支持
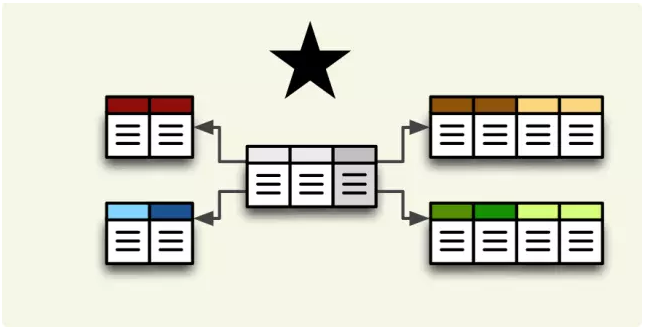
星型模型
适用于简单且直接的多维分析。它通过将一个中心事实表与多个维度表相连,简化了查询逻辑并提高了性能。
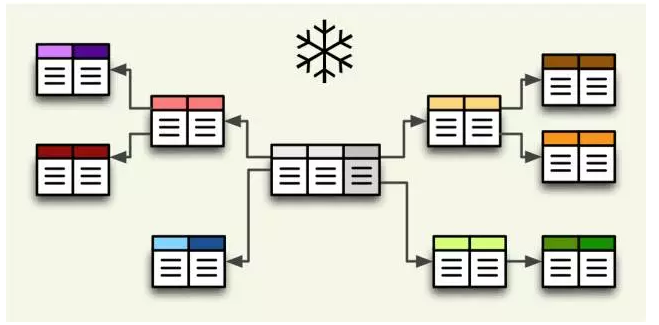
雪花模型
对于拥有复杂层次结构或需要减少数据冗余的情况,慧安蜂巢允许进一步规范化维度表,形成分支状结构,从而更精细地管理数据。
混合模型
结合两者优势,根据具体应用选择最合适的结构,平衡存储效率和查询速度。
动态模型
针对快速变化的业务环境,慧安蜂巢提供了一种动态调整模型的能力,使得数据仓库可以随着业务需求的变化而自适应调整,无需大规模重构。
02自动化与智能化建模工具
自动分区与索引生成
基于数据分析模式自动生成合理的分区策略和索引,加速查询响应时间。例如,平台可以根据时间戳字段自动创建按月、季度或年的分区,或者为频繁过滤条件创建索引。
智能推荐系统
利用机器学习算法分析历史查询模式,为用户提供最佳实践建议。比如,在创建新维度时,系统可以根据相似案例推荐适当的字段组合;在优化查询性能时,建议添加或删除特定索引。
模型健康检查
定期评估现有模型的有效性和性能,识别潜在问题并提出改进建议,如冗余数据清理、过期数据归档等。
03高级特性与定制化选项
复杂层次结构支持
对于具有深层嵌套关系的数据集,平台支持定义复杂的层次结构,并提供专门的查询语言来简化对这些层次的访问。
多版本控制
允许同时维护多个版本的模型,便于测试新功能而不影响生产环境。每个版本都可以独立配置参数,进行性能调优。
跨库关联查询
支持跨越多个数据库或数据源的联合查询,使得即使数据分散存储也能轻松整合分析。
用户自定义函数(UDF)
用户可以根据自己的业务逻辑编写SQL函数或使用Python/R脚本,增强数据处理的灵活性。
04数据治理与元数据管理
元数据管理
跟踪记录所有数据资产的来源、用途及变更历史,确保信息透明可追溯。
数据血缘追踪
可视化展示数据从源头到最终报表之间的流转路径,帮助理解数据依赖关系,便于故障排查和影响评估。
数据标准制定
建立统一的数据命名规则、格式规范等,促进不同部门间的协作沟通。
权限管理
细致划分用户角色及其对应的操作权限,保障敏感数据的安全性。
05实时更新与增量加载
流式ETL/ELT
支持从各种流式数据源(如Kafka, Flume)中提取数据,并即时转换加载至数据仓库,确保数据最新鲜准确。
微批处理
采用微批处理方式,定期捕获少量新增或修改的数据,减小对源系统的压力,同时也减少了全量加载带来的资源浪费。
双写一致性
在某些情况下,可能需要同时更新多个目标系统,慧安蜂巢提供了双写一致性保障,确保所有副本之间的一致性。
06总结
慧安蜂巢大数据平台通过多样化建模方法的支持、自动化与智能化工具的应用、高级特性与定制化选项的提供、严格的数据治理措施以及高效的实时更新机制,在数仓建模领域树立了新的标杆。这不仅帮助企业解决了传统数据仓库面临的诸多挑战,更为企业在数字经济时代的成功转型注入了新的活力。选择慧安蜂巢,即选择了通往数据驱动未来的可靠伙伴。
往期回顾
工作流引擎革新:赋能企业运营,实现高效自动化管理
夏至到来,点击查看防暑小贴士!
来源:| 研发中心
审核:| 市场部与公共关系部